Executor是Spark分布式运行的承载,其会分布在不同的Worker节点上的线程池中运行。本章节尝试通过剖析Executor的源码Executor.scala,以分析实现的细节,帮助读者在实际工作中定位与调试问题。
此源码实现了Executor类及其伴生对象。Executor类属于Spark内核中很关键的一个组成部分,是Worker节点中Spark任务运行的承载。通过外围一系列的切分、调度、分解等,形成可运行的Task,由Worker节点上的NM容器启动执行。从此源码整体大的情况来看,Executor包含了TaskReaper和TaskRunner两个子类,还有两个私有的线程池threadPool和taskReaperPool,如下图所示:
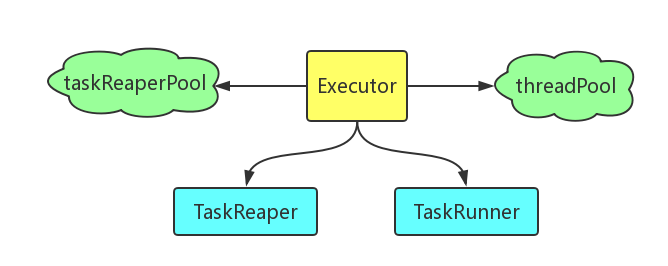
其中,TaskReaper用于管理杀死或取消一个Task的过程,并且需要监控这个Task直到其结束,后面进一步的源码分析会说明,TaskReaper的设计是很精妙的,考虑了用户多次发起杀死或取消的要求;TaskRunner则是包装了需要执行的Task。
整体来看,这部分代码相对较长,功能较多,实现了Task相关线程的管理,包括相关线程池的建立、Task的启停、心跳信号的处理、通过ThreadMXBean获取到各种线程管理方面的信息、建立任务的各种监测指标、相关Task及其依赖的序列化或反序列化(便于发送到分布式Worker节点上执行)等等。以下尝试对其主要功能进行详细剖析:
2.1 Executor类的初始化
Scala的主构造函数的写法比较简洁,直接写在类定义内部,而不用像Java一样需要一个与类同名的构造函数定义,这点大家在阅读源码时需要注意。可以看到,Executor类内部定义了一系列私有的成员变量,用于记录相应的属性及状态,大部分都是val不可变量,只有个别类似heartbeatFailures的可变量,很好的遵循了Scala函数式代码风格,尽可能的减少了变量带来的副作用(这点初学者可能难于理解,建议参考《Scala函数式编程》一书)。另外,也定义了一些对外的成员函数,还有最主要的TaskReaper和TaskRunner两个子类。由于Scala的类定义和主构造函数一般是写在一起的,所以阅读源码时需要注意理清初始化的逻辑主线。这里摘选了Executor类的初始化部分代码如下(其中有些次要部分使用…省略):
[org.apache.spark.executor]
[Executor.scala]
...
logInfo(s"Starting executor ID $executorId on host $executorHostname")
// Application dependencies (added through SparkContext) that we've fetched so far on this node.
// Each map holds the master's timestamp for the version of that file or JAR we got.
private val currentFiles: HashMap[String, Long] = new HashMap[String, Long]()
private val currentJars: HashMap[String, Long] = new HashMap[String, Long]()
private val EMPTY_BYTE_BUFFER = ByteBuffer.wrap(new Array[Byte](0))
private val conf = env.conf
// No ip or host:port - just hostname
Utils.checkHost(executorHostname, "Expected executed slave to be a hostname")
// must not have port specified.
assert (0 == Utils.parseHostPort(executorHostname)._2)
// Make sure the local hostname we report matches the cluster scheduler's name for this host
Utils.setCustomHostname(executorHostname)
if (!isLocal) {
// Setup an uncaught exception handler for non-local mode.
// Make any thread terminations due to uncaught exceptions kill the entire
// executor process to avoid surprising stalls.
Thread.setDefaultUncaughtExceptionHandler(uncaughtExceptionHandler)
}
// Start worker thread pool
private val threadPool = ...
private val executorSource = new ExecutorSource(threadPool, executorId)
// Pool used for threads that supervise task killing / cancellation
private val taskReaperPool = ThreadUtils.newDaemonCachedThreadPool("Task reaper")
// For tasks which are in the process of being killed, this map holds the most recently created
// TaskReaper. All accesses to this map should be synchronized on the map itself (this isn't
// a ConcurrentHashMap because we use the synchronization for purposes other than simply guarding
// the integrity of the map's internal state). The purpose of this map is to prevent the creation
// of a separate TaskReaper for every killTask() of a given task. Instead, this map allows us to
// track whether an existing TaskReaper fulfills the role of a TaskReaper that we would otherwise
// create. The map key is a task id.
private val taskReaperForTask: HashMap[Long, TaskReaper] = HashMap[Long, TaskReaper]()
if (!isLocal) {
env.metricsSystem.registerSource(executorSource)
env.blockManager.initialize(conf.getAppId)
}
// Whether to load classes in user jars before those in Spark jars
private val userClassPathFirst = conf.getBoolean("spark.executor.userClassPathFirst", false)
// Whether to monitor killed / interrupted tasks
private val taskReaperEnabled = conf.getBoolean("spark.task.reaper.enabled", false)
// Create our ClassLoader
// do this after SparkEnv creation so can access the SecurityManager
private val urlClassLoader = createClassLoader()
private val replClassLoader = addReplClassLoaderIfNeeded(urlClassLoader)
// Set the classloader for serializer
env.serializer.setDefaultClassLoader(replClassLoader)
// Max size of direct result. If task result is bigger than this, we use the block manager
// to send the result back.
private val maxDirectResultSize = ...
// Limit of bytes for total size of results (default is 1GB)
private val maxResultSize = Utils.getMaxResultSize(conf)
// Maintains the list of running tasks.
private val runningTasks = new ConcurrentHashMap[Long, TaskRunner]
// Executor for the heartbeat task.
private val heartbeater = ThreadUtils.newDaemonSingleThreadScheduledExecutor("driver-heartbeater")
// must be initialized before running startDriverHeartbeat()
private val heartbeatReceiverRef = ...
/**
* When an executor is unable to send heartbeats to the driver more than `HEARTBEAT_MAX_FAILURES`
* times, it should kill itself. The default value is 60. It means we will retry to send
* heartbeats about 10 minutes because the heartbeat interval is 10s.
*/
private val HEARTBEAT_MAX_FAILURES = conf.getInt("spark.executor.heartbeat.maxFailures", 60)
/**
* Count the failure times of heartbeat. It should only be accessed in the heartbeat thread. Each
* successful heartbeat will reset it to 0.
*/
private var heartbeatFailures = 0
startDriverHeartbeater()
可以看到,初始化过程主要分为如下几步:
- 使用logInfo输出executorId和executorHostname参数;
- 获取传入的SparkEnv类型参数env.conf配置信息;
- 检查主机名参数executorHostname,不可以为IP或者host:port的形式,并与集群scheduler中主机的名字匹配;
- 如果是非本地模式的话,设置默认的未捕获异常处理器,这个是构造函数的一个可选参数,默认值是SparkUncaughtExceptionHandler。主要用于当任何线程因为未捕获的异常终止时,杀死整个executor进程,以防止出现一些奇怪的且难以核查的僵尸进程情况;
- 创建线程池threadPool及taskReaperPool(参见后续详解);
- 如果是非本地模式的话,则在传入的spark环境env(SparkEnv类型)中的相关性能监控指标体系metricsSystem中注册与工作线程池threadPool关联的执行源对象;且执行env中的块管理器blockManager的初始化工作(块管理器属于Spark内核的Storage模块,它在每一个driver和executors节点上都会运行,提供了本地或远程存取相关块数据的能力,这些块数据存放在内存、磁盘等不同的介质上,块管理器使用前必须进行初始化);
- 获取spark.executor.userClassPathFirst参数,表示用户jar类库是否先于Spark类库加载;
- 获取spark.task.reaper.enabled参数,表示是否监控被杀死或中断的task;
- 获取类装载器ClassLoader(有urlClassLoader和replClassLoader两个);
- 设置spark环境env的序列化器serializer的默认类装载器为replClassLoader,这个是用于反序列化时进行类装载;
- 设定maxDirectResultSize,如果task的结果比这个值大,就会使用块管理器blockManager传回结果;
- 设定maxResultSize,最大的结果集大小,默认是1GB;
- 建立心跳线程heartbeater;
- 先初始化心跳信号接收器heartbeatReceiverRef,并获取spark.executor.heartbeat.maxFailures参数(心跳信号发送最大失败次数,如果executor发送心跳信号给driver的失败次数大于这个值,那么executor就会杀死自己的相关进程),在初始化心跳失败次数变量heartbeatFailures为0之后,调用私有成员函数startDriverHeartbeater正式启动心跳;
- 至此,Executor类构造函数的初始化结束,后面的源码定义了一些内部或外部的成员函数,以及TaskReaper和TaskRunner两个子类。
2.2 线程池threadPool及taskReaperPool详解
线程池threadPool用于管理具体工作线程,其通过com.google.common.util.concurrent.ThreadFactoryBuilder建立线程工厂,再通过标准的java.util.concurrent并发工具包提供的Executors.newCachedThreadPool建立线程池。详见如下源码:
[org.apache.spark.executor]
[Executor.scala]
...
import com.google.common.util.concurrent.ThreadFactoryBuilder
import java.util.concurrent._
...
以下代码为private[spark] class Executor内部:
private val threadPool = {
val threadFactory = new ThreadFactoryBuilder()
.setDaemon(true)
.setNameFormat("Executor task launch worker-%d")
.setThreadFactory(new ThreadFactory {
override def newThread(r: Runnable): Thread =
// Use UninterruptibleThread to run tasks so that we can allow running codes without being
// interrupted by `Thread.interrupt()`. Some issues, such as KAFKA-1894, HADOOP-10622,
// will hang forever if some methods are interrupted.
new UninterruptibleThread(r, "unused") // thread name will be set by ThreadFactoryBuilder
})
.build()
Executors.newCachedThreadPool(threadFactory).asInstanceOf[ThreadPoolExecutor]
}
...
可以看到,以上代码建立线程工厂时,设置了一些属性,包括设定了线程的名字格式”Executor task launch worker-%d”,重载newThread方法,建立一些不被Thread.interrupt()中断的线程等等,最后通过newCachedThreadPool建立线程池threadPool。注意,在Scala的函数式语义里,不可变变量threadPool所取的值是大括号对{}之间最后一条语句的返回值。 而另一个线程池taskReaperPool用于管理杀死或者取消Task所使用的线程,具体代码如下所示:
[org.apache.spark.executor]
[Executor.scala]
...
import org.apache.spark.util._
...
以下代码为private[spark] class Executor内部:
// Pool used for threads that supervise task killing / cancellation
private val taskReaperPool = ThreadUtils.newDaemonCachedThreadPool("Task reaper")
// For tasks which are in the process of being killed, this map holds the most recently created
// TaskReaper. All accesses to this map should be synchronized on the map itself (this isn't
// a ConcurrentHashMap because we use the synchronization for purposes other than simply guarding
// the integrity of the map's internal state). The purpose of this map is to prevent the creation
// of a separate TaskReaper for every killTask() of a given task. Instead, this map allows us to
// track whether an existing TaskReaper fulfills the role of a TaskReaper that we would otherwise
// create. The map key is a task id.
private val taskReaperForTask: HashMap[Long, TaskReaper] = HashMap[Long, TaskReaper]()
可以从以上代码的注释看到,为了防止每一次调用killTask都去生成一个独立的TaskReaper,需要一个称为taskReaperForTask的哈希表(哈希key是task id),我们可以根据这个哈希表去跟踪一个已有的TaskReaper是否已经完成了它的功能(杀死或取消Task),而不是去重新再新建一个TaskReaper。另外,考虑到我们需要的同步并不是简单的维护哈希表的内部状态就可以了,而是应该有更多的原子性方面的要求,所以我们没有使用并行哈希表ConcurrentHashMap,而是使用了普通的HashMap,并在访问时通过synchonrized实现同步。
2.3 子类TaskRunner详解
可以看到,TaskRunner子类实现了Runnable接口,说明这个子类的实例是需要由一个线程来执行的,可以着重关注其中的run方法。源码类定义的前面部分为该子类的初始化,需要注意的是,@volatile注解表示这个变量可以被多个线程同时更新,@GuardedBy(“TaskRunner.this”)注解表示后面这个变量只有获取了TaskRunner子类当前实例上的锁之后,才能访问。
其实TaskRunner就是把spark的一个Task包装起来运行,关于这个Task可以参考org.apache.spark.scheduler.Task类定义。spark中的Task分为两类:ShuffleMapTask和ResultTask,ShuffleMapTask和ResultTask类似于Hadoop中的Map和Reduce。spark的job分为一个或多个stage,最后一个stage包括一些ResultTask,之前的stage包括许多ShuffleMapTask。Task抽象类中包含了成员函数Run和一个空的RunTask,实际上,两类具体的Task都对基类的RunTask进行了重载,而且都增加了taskBinary的初始传入参数,在运行中对taskBinary进行反序列化从而完成一定的任务,如下图所示:
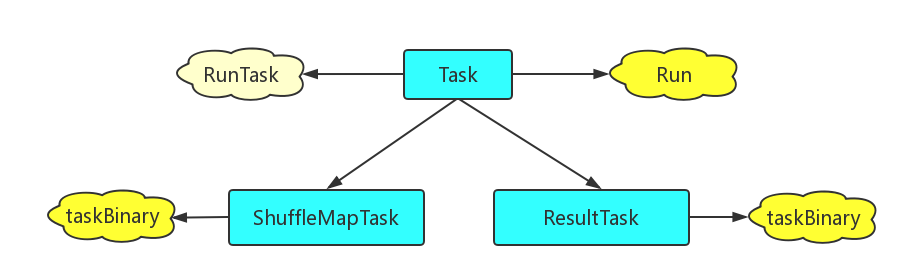
对于两类Task源码的进一步解读将在分析scheduler时深入进行。下面回到主线,对TaskRunner类的主干run方法进行分析:
- 创建threadMXBean、taskMemoryManager、deserializeStartTime、deserializeStartCpuTime等管理量;
- 设定replClassLoader为当前线程的类加载器;
- 建立spark环境中的序列化器env.closureSerializer的实例;
- 输出包含taskId及taskName的task日志、更新task状态;
- 然后进入一段被try包裹的真正反序列化、加载并执行task的代码,这段代码包括如下功能:
- 设置反序列化参数、更新依赖;
- 通过env.closureSerializer的实例对taskDescription.serializedTask进行反序列化;
- 设置task属性并传入taskMemoryManager;
- 判断在反序列化之前,该task是否已经被杀了,如果确实如此需要抛出TaskKilledException异常(源代码注释里面也解释了为啥不用return);
- 输出包含taskId和task.epoch的调试日志;
- 记录task开始时间及当前线程cpu占用时间;
- 设定一个threwException的布尔标志,用以表示在具体的task执行过程中是否有异常;
- 再次使用一个try…finally组合,通过调用task.run真正启动刚才反序列化的task,try中间仅仅包含了task.run代码,且将返回值传给value,最后的finally包含释放task的锁及清理内存等功能。需要注意的是,如果这里task.run的内部抛出了异常,虽然finally的清理工作仍会执行,但是后续会继续将这个异常抛向外层的catch子句,而且由于包含了!threwException条件,这里finally清理工作之后判断内存泄漏和各种锁是否释放干净的逻辑其实就没啥用了,外层只会得到task.run内部异常信息;
- 记录task结束时间及线程cpu占用;
- 将task的结果value序列化成valueBytes,并与汇聚的结果accumUpdates合并成DirectTaskResult对象,再把它序列化形成serializedDirectResult。如果结果大小大于maxResultSize,则丢弃它;如果大于maxDirectResultSize,则通过blockManager传送;否则,就直接发送给driver。
- 进入刚才try的catch段,开始处理各种异常。这里面,需要判断是否是被用户代码包含的task内部的异常,或者是task被杀,或者task中断,或者是task向HDFS提交输出时被driver拒绝,对于其它异常则会取得最新的汇聚值accums,并和具体异常信息一起打包序列化提供给driver;
- 最后的finally段,做收尾工作,从runningTasks的并发HashMap中移除当前的taskId。
至此,子类TaskRunner源码解读完毕,总的来说,TaskRunner从很高的抽象度上封装了task执行过程中所需要的一系列资源的监控、与driver之间的通信,包括具体task执行体、参数、结果集、异常等信息的序列化、反序列化等工作。通过这部分源码,TaskRunner很好的完成了一个具体task执行过程中需要考虑的方方面面的工作。
2.4 子类TaskReaper详解
子类TaskReaper主要用于杀死或者取消一个任务,它通过给具体任务发送中断标志,必要时发送中断线程调用Thread.interrupt(),并且监视这个任务直到它结束。Spark的任务杀死或取消机制的原则是:尽最大努力,因为有一些被标示为被杀的任务实际上并没有终止,这些僵尸任务占用了很多资源,导致新任务无法分配到必需的资源,处于资源饥饿状态。子类TaskReaper是在SPARK-18761更新任务时引入的,它提供了一种对僵尸任务的监控及清除机制,为了与以往的版本兼容,这个组件是需要显式的设置参数spark.task.reaper.enabled=true,才能打开。
一般的,一个任务只对应1个TaskReaper实例;不过,当Task的kill方法传入不同的interruptThread参数调用2次时,最多一个任务也能对应2个TaskReaper实例。一旦TaskReaper实例被创建,它将一直运行到它所负责监控的任务结束运行。
下面分析一下主干run方法:
先是定义一些起始时间startTimeMs、逝去时间elapsedTimeMs等统计量,然后在一个try块中去调用taskRunner.kill方法,而taskRunner.kill方法实际又调用了task.kill,再去看看task.kill,实际上是对任务打了一个结束标记,对这个结束标记的处理依赖于上层的代码;如果强行中断标志interruptThread为真的话,还会去调用线程的interrupt方法。接下去的任务实际上就是监控task运行直到其结束,这个本身概念不复杂,但是考虑到各种并发的场景,这里的同步机制需要解释一下。研究一下下面的代码:
while (!finished && !timeoutExceeded()) {
taskRunner.synchronized {
if (taskRunner.isFinished) {
finished = true
} else {
taskRunner.wait(killPollingIntervalMs)
}
}
...
}
在已结束标志为否及没有超时的条件下,上面的代码启动了一个循环,里面有一个读取taskRunner.isFinished标志及调用taskRunner.wait方法,这一小段逻辑是包含在taskRunner.synchronized里面的,大家有没有想过为什么?事实上,由于各线程的并行,在没有同步机制的情况下,很有可能上面的代码刚调用了taskRunner.isFinished结果为否,进入了else段,但同时task也确实已接近结束,在我们调用taskRunner.wait之前,task内部的finished标志已被置为真(注意:不是这里的这个局部变量finished),任务已经结束,这时再调用wait就可能陷入无效等待中,我们这里获得的结束标志也会不一致,后续还会导致不正确的警告信息和ThreadDump。所以,为了避免这一情况的出现,我们通过synchronized段来保证了上述判断和调用的整体原子性。
如果上面这个循环退出了,task仍没有结束,说明等待超时了:本地模式下,会输出错误信息,但不会终止JVM虚拟机;在非本地模式下,会通过抛出未捕获异常使JVM虚拟机退出。
在最后的收尾处理部分,需要维护一下taskReaperForTask哈希表,一个task最多有两个TaskReaper,前一个使用interruptThread==false调用,后一个使用interruptThread==true调用,源码里面在删除哈希表里面这个项时特地判断了一下,要删的TaskReaper实例是否是自身,如果不是的话一定是第二个调用的TaskReaper实例覆盖了前一个(源码里面很有意思的写了个空的else块,里面只有注释,说明作者还是很敬业的)。
至此,子类TaskReaper解析完毕,这个子类比较短,阅读源码的时候注意并发的一些特殊处理就可以了。