项目背景
自从2016年AlphaGo击败人类围棋选手,将时代带入了人工智能时代。无论机器机器学习还是深度学习,都依赖于数据。所以我们不得不回顾下这个10年在IT业中重要的名词。
云计算(Cloud):对云计算的定义有多种说法。现阶段广为接受的是美国国家标准与技术研究院定义:云计算是一种按使用量付费的模式,这种模式提供可用的、便捷的、按需的网络访问, 进入可配置的计算资源共享池(资源包括网络,服务器,存储,应用软件,服务),这些资源能够被快速提供,只需投入很少的管理工作,或与服务供应商进行很少的交互。
大数据(BigData):对于大数据的定义业界通常用4个V来解释 (即Volume、Variety、Value、Velocity),数据体量大,数据类型多,价值密度低,数据产生快。随着设备日志数据的剧增,日志数据本身也渐渐的往大数据的形态靠拢。
物联网(IoT):从最初在1999年提出:即通过射频识别(RFID)到现在物联网(Internet of Things),把所有物品通过信息传感设备与互联网连接起来,进行信息交换,即物物相息,以实现智能化识别和管理。
人工智能(AI):意图了解智能的实质,并生产出一种新的能以人类智能相似的方式做出反应的智能机器,该领域的研究包括机器人、语言识别、图像识别、自然语言处理和专家系统等。
项目内容
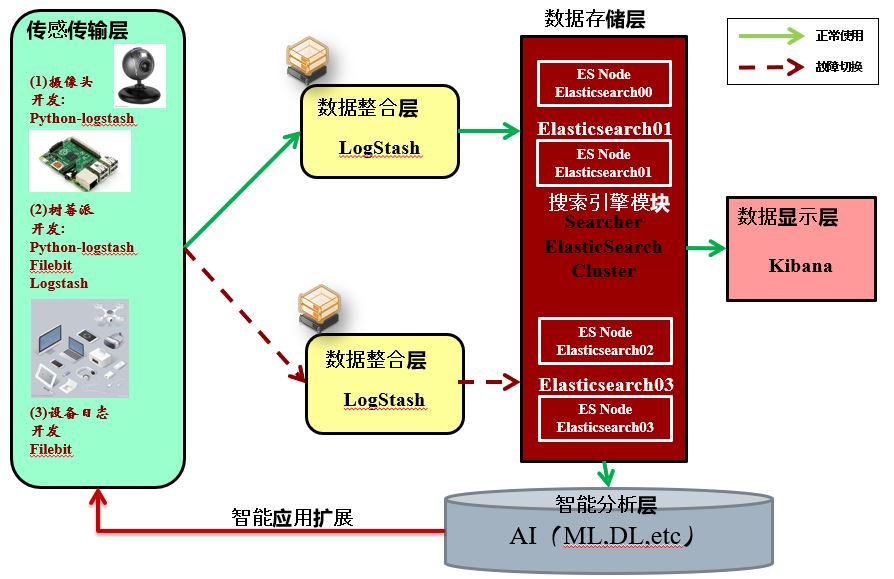
会使用Elastic公司的三款开源工具来进行IoTHub的构建。Elastic提供Logstash,Elasticsearch,Kibana这3款开源工具。其中Logstash为数据收集,转换,传输的工具,Elasticsearch为数据存储,搜索,分析的工具,Kibana为数据可视化展示的工具。

系统架构
Elasticsearch是分布式数据库,所以建立多台服务器做ES集群。Logstash主要起到传输作用,构建并行服务器。Kibana主要用于显示,构建单台。智能分析通过Python来进行。传感器部分通过Raspberry Pi 3等
硬件准备清单
为了简便,实验环境在Windows10中进行,真实环境可以考虑Windows Server 2016等服务器版本。
物理机:
CPU:I7 4770K,内存:32GB,硬盘:2块SSD 256GB,显卡:nvidia 1070 8G
虚拟机:
Server1:Windows 2012R2.(ElasticSearch,LogStash,Kibana),IP:192.168.1.201
Server2: Windows 2012R2.(ElasticSearch,LogStash),IP:192.168.1.202
Server3: Windows 2012R2.(ElasticSearch),IP:192.168.1.203
软件准备清单
Windows环境下安装ELK需要准备软件 Java8安装包(不要安装Java10!,不要安装Java10!,不要安装Java10!目前Logstash还不支持Java10.重要的要说3边) ElasticSearch安装包,LogStash安装包,Kibana安装包,nssm安装包。 另外还有node安装包与head插件(之后会说明)
第一步JAVA安装JAVA安装
Java8下载地址,请下载Windows x64版,目前为(jdk-8u171-windows-x64.exe)
http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
按默认安装。分别在虚拟Server1到3中安装。
第二步ElasticSearch安装
1.安装ELK首先需要到
https://www.elastic.co/cn/products
下载软件。目前为6.2.4版本建议使用MSI版本软件包
2.首先在Server1中安装第一台ElasticSearch,双击MSI软件包安装。
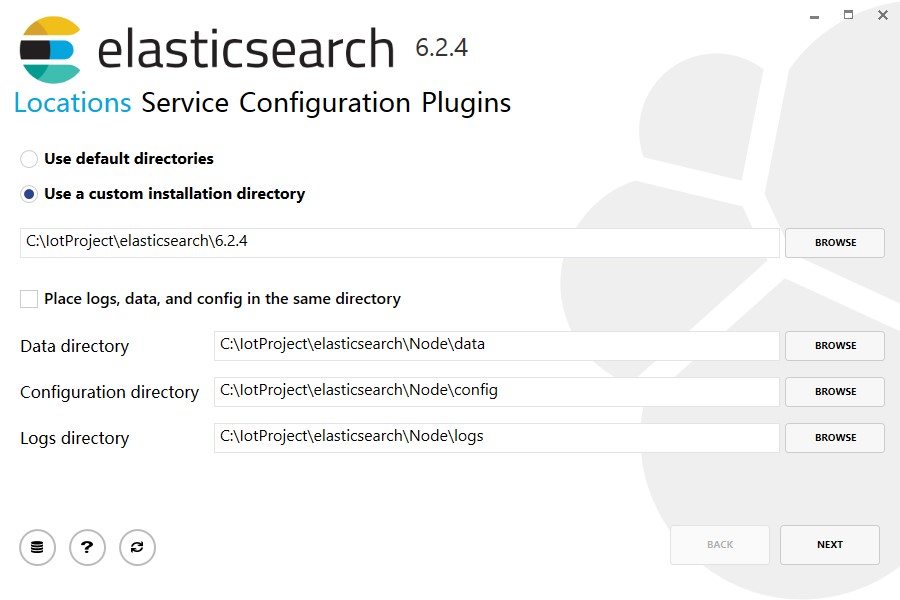
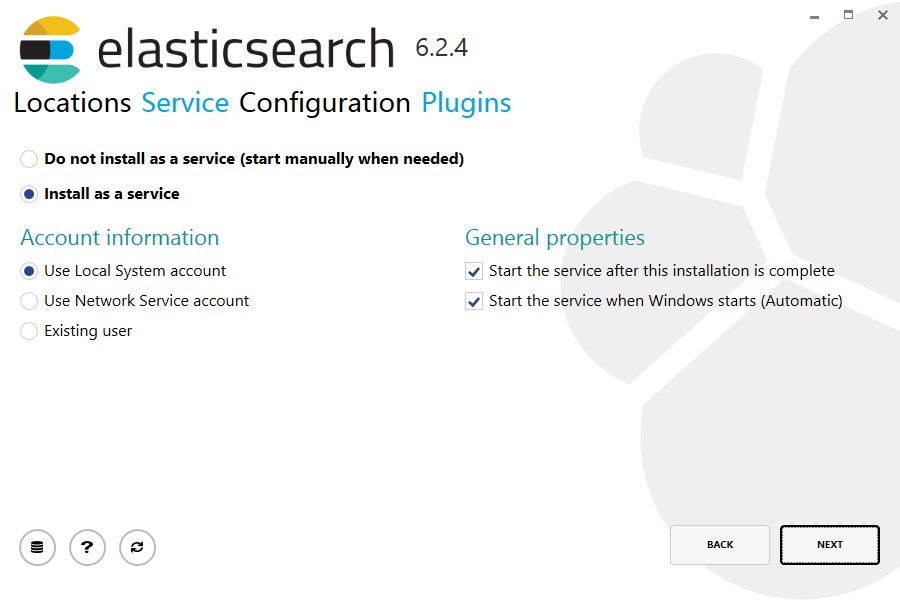
之后向导中不用选插件。下一步进行安装。
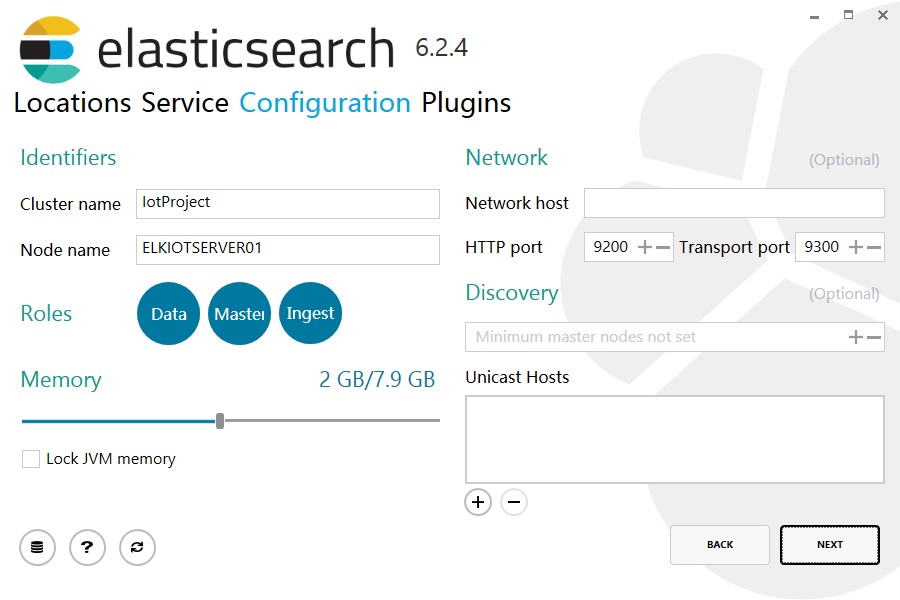
3.修改ES配置文件
修改以下配置文件
C:\IotProject\elasticsearch\Node\config\elasticsearch.yml
bootstrap.memory_lock: false
cluster.name: IotProject
network.host: 192.168.1.201 //绑定本地IP,默认尾127.0.0.1
http.port: 9200
http.cors.enabled: true //head插件用
http.cors.allow-origin: "*" //head插件用
node.data: true
node.ingest: true
node.master: true
node.max_local_storage_nodes: 1
node.name: ELKIOTSERVER01
path.data: C:\IotProject\elasticsearch\Node\data
path.logs: C:\IotProject\elasticsearch\Node\logs
transport.tcp.port: 9300
discovery.zen.ping.unicast.hosts: ["192.168.1.201","192.168.1.202","192.168.1.203"] //集群节点所有IP地址
discovery.zen.minimum_master_nodes: 2 //宣告master节点数,一般是节点数/2+1
细节可以参考以下URL https://blog.csdn.net/zxf_668899/article/details/54582849
4.Head插件安装(监控ElasticSearch状态)
参考以下URL安装
https://blog.csdn.net/u012270682/article/details/72934270
elasticsearch 5以上版本安装head需要安装node和grunt
下载地址:https://nodejs.org/en/download/ 根据自己系统下载相应的msi,双击安装。
确认node版本,并安装grunt,用npm install -g grunt -cli命令
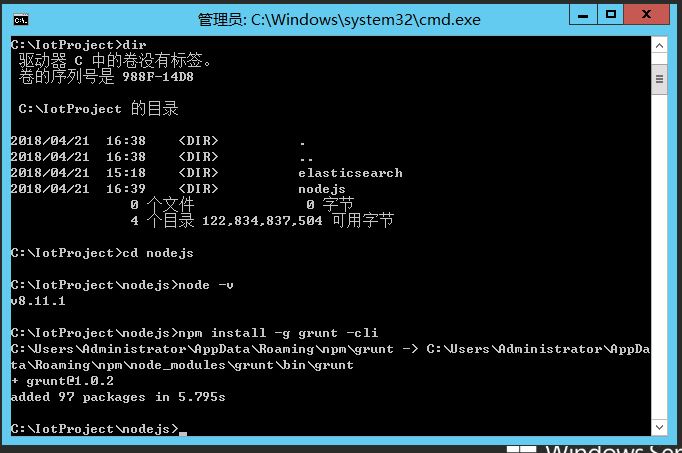
确认grunt版本,用grunt -version命令
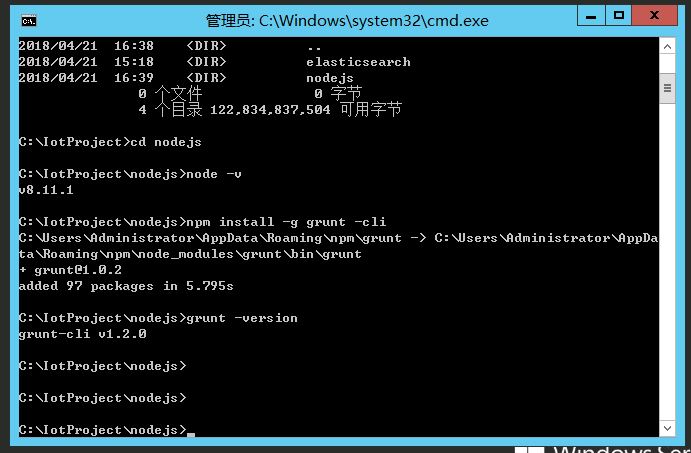
完成后,修改elasticsearch.yml配置文件
http.cors.enabled: true //head插件用
http.cors.allow-origin: “*” //head插件用
重启服务器。并到https://github.com/mobz/elasticsearch-head 下载zip文件,解压缩到文件夹
进入解压缩文件夹,修改Gruntfile.js文件
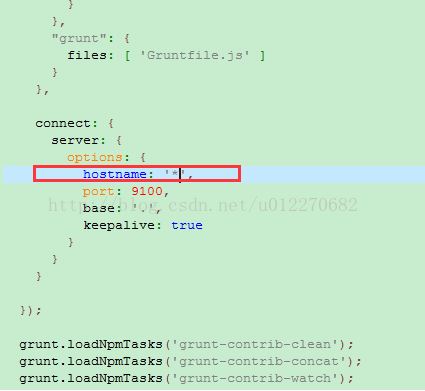
cmd进入E:\elasticsearch-5.4.1\elasticsearch-head-master文件夹
执行 npm install
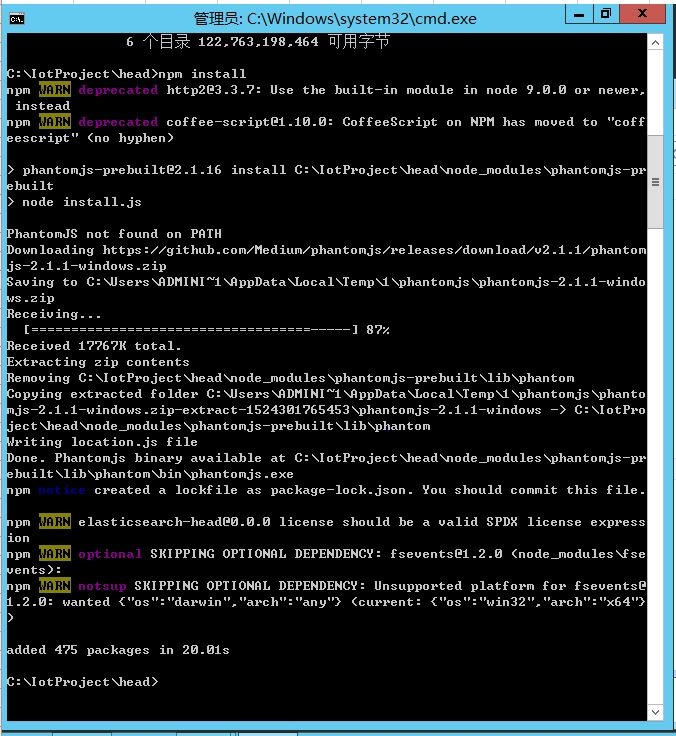
安装完成查看结果192.168.1.201:9100确认结果。目前没数据的话,如图
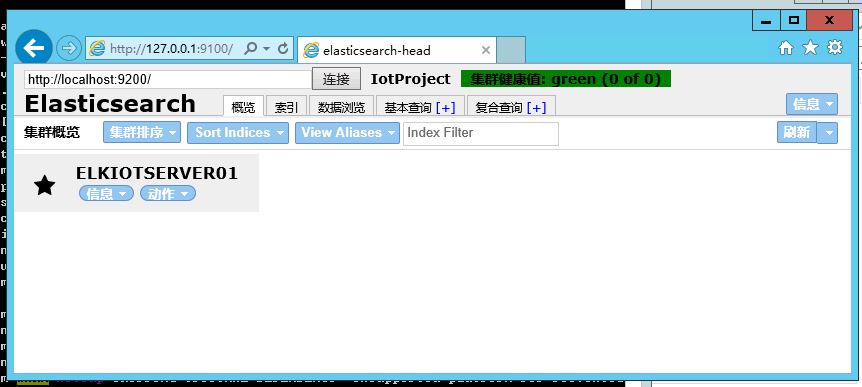
安装完成执行grunt server 或者npm run start
或head解压缩目录下创建该命令bat文件
6.按上述2-3内容,在server2,与server3中安装。其他ES集群节点 其他节点node.data: true,node.ingest: true,node.master: true。 但是head插件用配置不用追加。
ElasticSearch介绍
使用ElasticSearch搜索引擎,如图所示,从集群(Cluster),节点(Node),索引(Index),分片(Shard)的4个内容
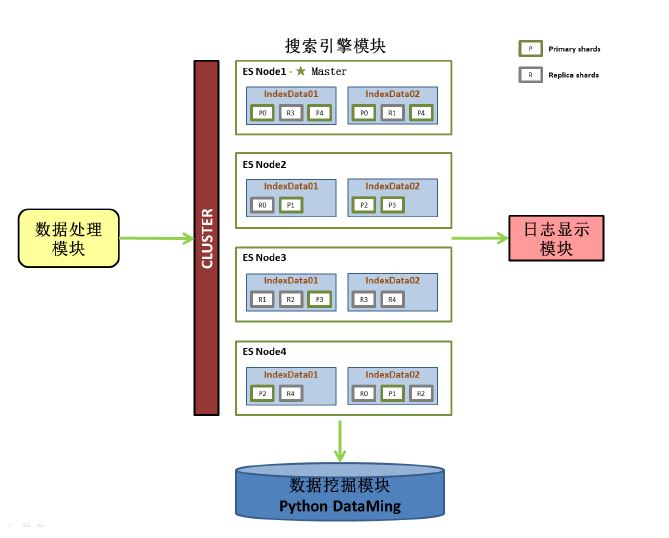
●集群(Cluster):
集群就是一个或多个节点存储数据,其中一个节点为主节点,这个主节点是可以通过选举产生的,并提供跨节点的联合索引和搜索的功能。集群有一个唯一性标示的名字,默认是elasticsearch,集群名字很重要,每个节点是基于集群名字加入到其集群中的。因此,确保在不同环境中使用不同的集群名字。一个集群可以只有一个节点。强烈建议在配置elasticsearch时,配置成集群模式。
目的:建立一组拥有相同集群名的节点集合,它们协同作业并共享数据并提供
故障转移和弹性扩展,一个集群也可以由一个单一节点创建。
●节点(Node):
节点就是一台单一的服务器,是集群的一部分,存储数据并参与集群的索引和搜索功能。像集群一样,节点也是通过名字来标识,默认是在节点启动时随机分配的字符名。当然啦,你可以自己定义。该名字也蛮重要的,在集群中用于识别服务器对应的节点
目的 :运行Elasticsearch的实例。节点间通过网络进行通讯协作作业(默认是TCP 9300端口)。
集群中会有一台包涵Master模式的节点,当Master模式节点故障后,会由可升级Master节点中选择出来,并提升为Master。
·默认节点(包括可升级Master,存储Data,聚合Query)
·Master节点:集群中用于控制其他节点的工作。
·数据节点:仅存放分片数据的节点
·聚合查询节点:对外部应用程序的查询进行响应。无数据和Master
●索引(Index):
索引是有几分相似属性的一系列文档的集合。如nginx日志索引、syslog索引等等。索引是由名字标识,名字必须全部小写。这个名字用来进行索引、搜索、更新和删除文档的操作。
索引相对于关系型数据库的库。
目的:存储关联数据的地方。实际上,索引只是一个用来指向一个或多个分片(shards)的逻辑命名空间。
●类型(Type) 在一个索引中,可以定义一个或多个类型。类型是一个逻辑类别还是分区完全取决于你。通常情况下,一个类型被定于成具有一组共同字段的文档。如ttlsa运维生成时间所有的数据存入在一个单一的名为logstash-ttlsa的索引中,同时,定义了用户数据类型,帖子数据类型和评论类型。 类型相对于关系型数据库的表。
●文档(Document) 文档是信息的基本单元,可以被索引的。文档是以JSON格式表现的。 在类型中,可以根据需求存储多个文档。 虽然一个文档在物理上位于一个索引,实际上一个文档必须在一个索引内被索引和分配一个类型。 文档相对于关系型数据库的列。
●分片(Shard):
在实际情况下,索引存储的数据可能超过单个节点的硬件限制。如一个十亿文档需1TB空间可能不适合存储在单个节点的磁盘上,或者从单个节点搜索请求太慢了。为了解决这个问题,elasticsearch提供将索引分成多个分片的功能。当在创建索引时,可以定义想要分片的数量。每一个分片就是一个全功能的独立的索引,可以位于集群中任何节点上。
分片的两个最主要原因:
a、水平分割扩展,增大存储量
b、分布式并行跨分片操作,提高性能和吞吐量
分布式分片的机制和搜索请求的文档如何汇总完全是有elasticsearch控制的,这些对用户而言是透明的。
网络问题等等其它问题可以在任何时候不期而至,为了健壮性,强烈建议要有一个故障切换机制,无论何种故障以防止分片或者节点不可用。
为此,elasticsearch让我们将索引分片复制一份或多份,称之为分片副本或副本。
副本也有两个最主要原因:
高可用性,以应对分片或者节点故障。出于这个原因,分片副本要在不同的节点上。
提供性能,增大吞吐量,搜索可以并行在所有副本上执行。
总之,每一个索引可以被分成多个分片。索引也可以有0个或多个副本。复制后,每个索引都有主分片(母分片)和复制分片(复制于母分片)。分片和副本数量可以在每个索引被创建时定义。索引创建后,可以在任何时候动态的更改副本数量,但是,不能改变分片数。
默认情况下,elasticsearch为每个索引分片5个主分片和1个副本,这就意味着集群至少需要2个节点。索引将会有5个主分片和5个副本(1个完整副本),每个索引总共有10个分片。
每个elasticsearch分片是一个Lucene索引。一个单个Lucene索引有最大的文档数LUCENE-5843, 文档数限制为2147483519(MAX_VALUE – 128)。 可通过_cat/shards来监控分片大小。
目的 :提供 最小级别工作单位,它只是保存了索引中所有数据的一部分。分片作为数据容器,日志数据存储在分片之中,然后分片被动态的分配到集群的各个节点,随着集群的扩容或缩小,Elasticsearch会将分片自动在节点中进行迁移,保证集群的动态平衡。
针对每个索引,分为0-4的5个分片,且有1组主分片与1组复制片。也就是供有10个分片,分在在3台主机中。
其原因为分片按特性会分为:
·主分片(primary shard) : 索引创建时会将主分片的数量固定了,但是复制分片的数量可以之后进行调整。
·复制分片(replica shard): 复制分片是主分片的副本,当主分片所在主机故障时,可以继续提供读请求,如搜索或者从别的分片中读取文档。
通过触发分片访问的概率,来提升ElasticSearch集群的性能。
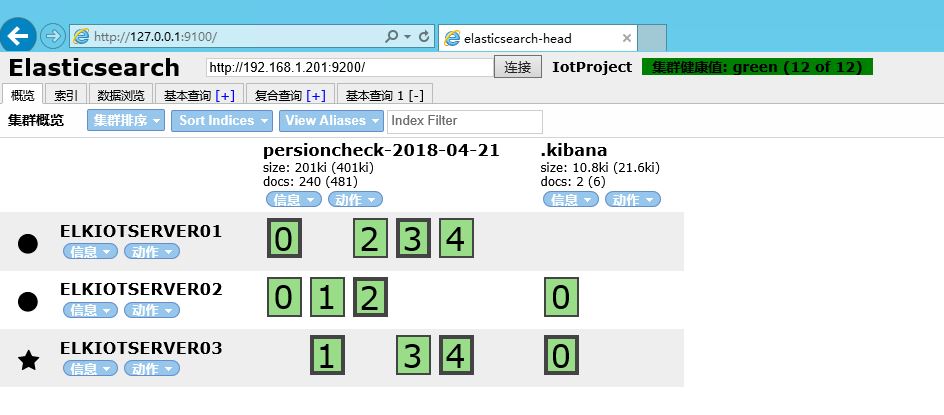
(1)集群状态: green:主分片、副本分片都存在 yellow:分片丢失,但每个分片至少存在一个主分片或副本分片 red:分片丢失,主分片和副本分片都丢失
(2)Lucene的核心组件: 索引(Index):类比数据库(database) 类型(Type):类比表(table) 文档(Document):类比行(row)
(3)Elasticsearch提供了RESTful的API接口,可以通过http协议与其进行交互
语法:curl -X
<BODY>:json格式的请求主体
<VERB>:GET(获取),POST(修改),PUT(创建),DELETE(删除)
<PATH>:/index_name/type/Document_ID/
特殊PATH:/_cat, /_search, /_cluster
创建文档:-XPUT -d '{"key1": "value1", "key2": value, ...}'
/_search:搜索所有的索引和类型;
/INDEX_NAME/_search:搜索指定的单个索引;
/INDEX1,INDEX2/_search:搜索指定的多个索引;
/s*/_search:搜索所有以s开头的索引;
/INDEX_NAME/TYPE_NAME/_search:搜索指定的单个索引的指定类型;
curl -XGET 'http://192.168.1.201:9200/_cluster/health?pretty=true'
curl -XGET 'http://192.168.1.201:9200/_cluster/stats?pretty=true'
curl -XGET 'http://192.168.1.201:9200/_cat/nodes?pretty'
curl -XGET 'http://192.168.1.201:9200/_cat/health?pretty'
第三部LogStash安装
1.将下载的LogStash文件解压缩到制定的目录中。同时在bin目录中,创建一个启动bat
C:\IotProject\Logstash\6.2.4\bin该目录下创建。
Bat文件如下
logstash -f conf\IotProject.conf
其中 -f为执行conf文件。-e为直接执行命令行中的配置程序。一般用-f
2.创建conf配置文件。
(1)IotProject.conf
input {
tcp{
port => 5000
codec => json
}
}
#filter {
#}
output {
elasticsearch{
hosts => ["192.168.1.201:9200","192.168.1.202:9200","192.168.1.203:9200"]
index => "persioncheck-%{+YYYY-MM-dd}"
document_type => "persioncheck"
}
}
(2)debug用conf
input {
tcp{
port => 5000
codec => json
}
}
#filter {
#}
output {
stdout{
codec => rubydebug
}
}
2.使用nssm将logstash作为windows服务启动
到http://www.nssm.cc/download 下载最新版本nssm并拷贝到项目目录。
参考 https://www.cnblogs.com/TianFang/p/7912648.html 设定logstash服务,nssm install logstash命令
path为logstash刚才创建的bat文件。
Dependencies为依赖elasticsearch,并填写es的服务名称。
LogStash介绍
1.Logstash日志管道工具进行构建。 使用其中的Input组件、Filter组件、Output组件作为构造块进行设计,
input {
tcp{
port => 5000 //TCP端口
codec => json //将数据转为json
}
}
output {
elasticsearch{
hosts => ["192.168.1.201:9200","192.168.1.202:9200","192.168.1.203:9200"] //写入到3台es服务器。IP都要
index => "persioncheck-%{+YYYY-MM-dd}" //索引的名称 - 日期
document_type => "persioncheck" //文档类型名称
}
}
内容可以参考URL https://www.cnblogs.com/moonlightL/p/7760512.html
2.filter功能
如图主要有以下功能
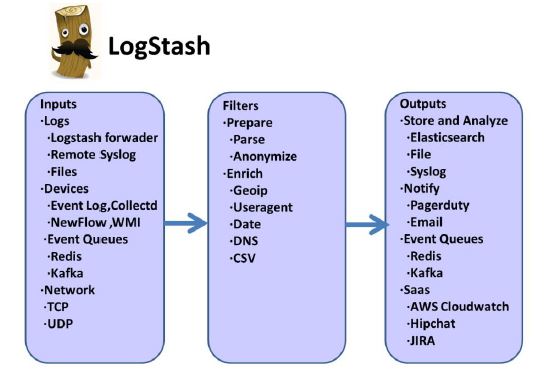
部分举例(本代码中无使用filter)
filter {
if [type] == "WindowsEventLog" {
grok {
match => [ "host", "^(?<host2>[0-2]?[0-9]?[0-9]\.[0-2]?[0-9]?[0-9]\.[0-2]?[0-9]?[0-9]\.[0-2]?[0-9]?[0-9]):.*" ]
}
mutate {
replace => [ "host", "%{Hostname}" ]
}
mutate {
remove_field => [ "host2" ]
}
mutate {
lowercase => [ "EventType", "FileName", "Hostname", "Severity" ]
}
mutate {
rename => [ "Hostname", "source_hostname" ]
}
mutate {
gsub => ["source_hostname","\.example\.com",""]
}
date {
match => [ "EventTime", "YYYY-MM-dd HH:mm:ss" ]
}
mutate {
rename => [ "Severity", "evt_severity" ]
rename => [ "SeverityValue", "evt_severityvalue" ]
rename => [ "Channel", "evt_channel" ]
rename => [ "SourceName", "evt_program" ]
rename => [ "SourceModuleName", "nxlog_evt" ]
rename => [ "Category", "evt_category" ]
rename => [ "EventID", "evt_ID" ]
rename => [ "RecordNumber", "evt_recordnumber" ]
rename => [ "ProcessID", "evt_processID" ]
}
if [SubjectUserName] =~ "." {
mutate {
replace => [ "AccountName", "%{SubjectUserName}" ]
}
}
if [TargetUserName] =~ "." {
mutate {
replace => [ "AccountName", "%{TargetUserName}" ]
}
}
if [FileName] =~ "." {
mutate {
replace => [ "evt_category", "%{FileName}" ]
}
}
mutate {
lowercase => [ "AccountName", "evt_channel" ]
}
mutate {
remove => [ "SourceModuleType", "EventTimeWritten", "EventReceivedTime", "EventType" ]
}
if [evt_program] == "WSH"{
grok{
match => ["message",".*scriptname\s(?<script_name>\b\w*\b)\s.*scriptID\s(?<script_ID>\b\w*\b)\s.*scriptresult\s(?<script_result>\b\w*\b)\s.*scriptmessage\s(?<script_message>.*)"]
}
mutate {
replace => [ "message", "%{script_message}" ]
}
mutate {
remove_field => [ "script_message" ]
}
}
}
if [type] == "DDWRT"{
grok {
match => ["message" ,".*>(?<msMonth>.*)\s(?<msDay>.*)\s(?<msTimes>.*)\skernel:\s(?<Action>\b\w*\b)\s.*SRC=(?<from_srcip>[0-2]?[0-9]?[0-9]\.[0-2]?[0-9]?[0-9]\.[0-2]?[0-9]?[0-9]\.[0-2]?[0-9]?[0-9])\sDST=(?<to_dstip>[0-2]?[0-9]?[0-9]\.[0-2]?[0-9]?[0-9]\.[0-2]?[0-9]?[0-9]\.[0-2]?[0-9]?[0-9]).*PROTO=(?<protocol>\b\w*\b)\sSPT=(?<from_spt>\b\w*\b)\sDPT=(?<to_dpt>\b\w*\b).*"]
}
grok {
match => ["message" ,".*>(?<EventTime>.*)\skernel:\s(?<Action>\b\w*\b)\s.*SRC=(?<from_srcip>[0-2]?[0-9]?[0-9]\.[0-2]?[0-9]?[0-9]\.[0-2]?[0-9]?[0-9]\.[0-2]?[0-9]?[0-9])\sDST=(?<to_dstip>[0-2]?[0-9]?[0-9]\.[0-2]?[0-9]?[0-9]\.[0-2]?[0-9]?[0-9]\.[0-2]?[0-9]?[0-9]).*PROTO=(?<protocol>\b\w*\b)\sSPT=(?<from_spt>\b\w*\b)\sDPT=(?<to_dpt>\b\w*\b).*"]
}
grok {
match => ["@timestamp" ,"(?<stampYear>.*)-.*"]
}
mutate {
add_tag => [ "EventTime" ]
replace => [ "EventTime", "%{msMonth} %{msDay} %{msTimes}" ]
}
date {
match => [ "EventTime", "MMM dd HH:mm:ss","MMM d HH:mm:ss" ]
}
}
}
(1)Grok过滤模块
目的:解析任意文本,将非结构日志数据结构化的模块。
分析:通过子函数Match调用实现正则表达式匹配来结构化日志数据。
(2)Date处理模块
目的:将日志数据中的时间返回给“@timestamp”。
分析 :它是一种标准的 ISO8601 的时间戳,其结果类似于
“2015 -08 -16T00:49:32.000Z” 。 通过子函数Match调用完成时间格式的
匹配来反馈数据。时间格式为“YYYY-MM-dd HH:mm:ss”
(3) Mutate 处理模块
目的:对主机日志 数据进行重命名、 删除替换修改。
分析:通过子函数调用
Replace :数据 替换,通过 替换,通过 %{ 结构字段名 }将 host 替换 成 hostname 字段数据 。
Lowercase :将”EventType”, Hostname”, Severity” “EventType”, Hostname”, Severity” “EventType”, Hostname”, Severity” 数据 改为小写字符串。
Rename :重命名 结构字段的名称。 将”Hostname” 重命名为 “source_hostname” 。
Gsub:替换日志数据中的字符串格式。将”source_hostname”中的域名
如”.ComingSpace.local”替换为空。
Remove:删除日志数据中的结构字段。删除”SourceModuleType”、
“EventTimeWritten”、 “EventReceivedTime”字段及数据。
第四步kibana的安装
将kibana拷贝到文件夹,并制作bat文件。 用nssm将kibana作为服务启动。
kibana需要修改配置kibana.yml
server.port: 5601
server.host: “192.168.1.201”
elasticsearch.url: “http://192.168.1.201:9200”
然后打开URL
192.168.1.201:5601
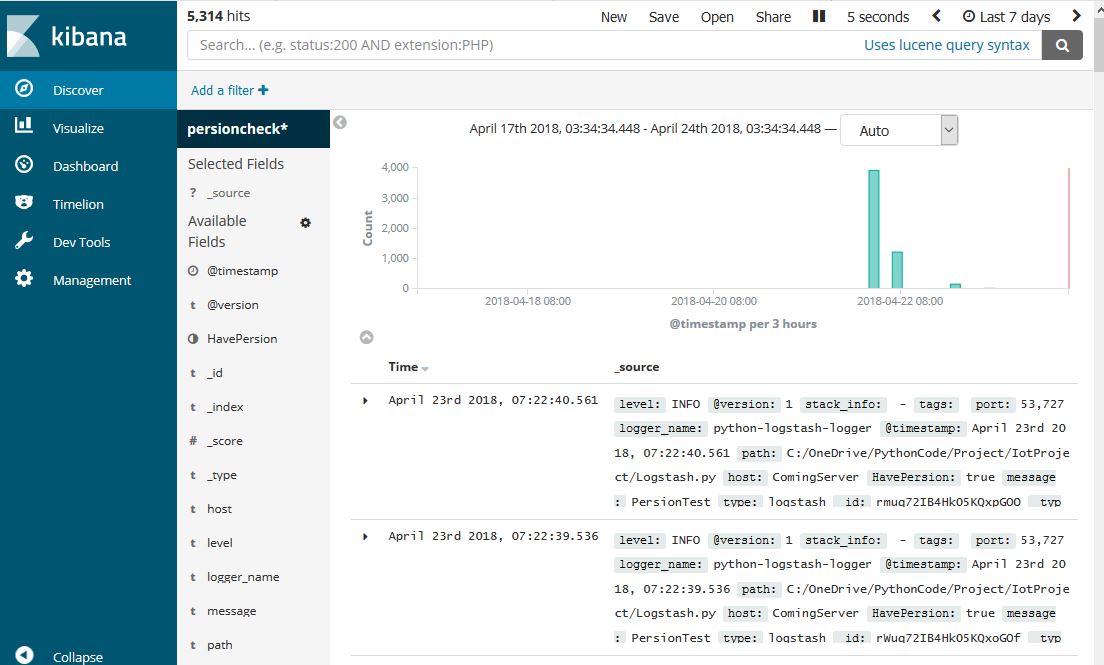
kibana今后可以绑定地图,根据gps做应用。本次未进行实验。
第五步应用传感器
我们通过电脑结合opencv来对人脸进行检查,并提交数据给ELK
我们需要安装python-logstash。可以直接通过python传输数据
https://pypi.org/project/python-logstash/
通过命令行,pip install python-logstash安装
然后编写代码
import logging
import logstash
import cv2
import time
host = '192.168.1.201'
test_logger = logging.getLogger('python-logstash-logger')
test_logger.setLevel(logging.INFO)
test_logger.addHandler(logstash.TCPLogstashHandler(host, 5000, version=1)
cap=cv2.VideoCapture(0)
face_cascade = cv2.CascadeClassifier("C:/OneDrive/PythonCode/Configfile/OpenCV/haarcascade_frontalface_default.xml")
while (True):
# Capture frame-by-frame
ret, frame = cap.read()
# Our operations on the frame come here
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
# The detected objects are returned as a list of rectangles
faces = face_cascade.detectMultiScale(gray, 1.3, 5)
for (x, y, w, h) in faces:
cv2.rectangle(frame, (x, y), (x + w, y + h), (0, 255, 0), 2)
# Display the resulting frame
extra = {
'HavePersion': True,
}
test_logger.info('PersionTest', extra=extra)
cv2.imshow('frame', frame)
time.sleep(1)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
# Closes video file or capturing device.
cap.release()
cv2.destroyAllWindows()
确认kibana是否已经有数据进行传入。本次实验到这里。谢谢大家。