by @寒小阳
部分内容整理自互联网,感谢众多同学的分享。
1.前言
目前的图像和自然语言处理很多地方用到了神经网络/深度学习相关的知识,神奇的效果让广大身处IT一线的程序猿GG们跃跃欲试,不过看到深度学习相关一大串公式之后头皮发麻,又大有放弃的想法。
从工业使用的角度来说,不打算做最前沿的研究,只是用已有的方法或者成型的框架来完成一些任务,也不用一上来就死啃理论,倒不如先把神经网络看得简单一点,视作一个搭积木的过程,所谓的卷积神经网络(CNN)或者循环神经网络(RNN)等无非是积木块不一样(层次和功能不同)以及搭建的方式不一样,再者会有一套完整的理论帮助我们把搭建的积木模型最好地和需要完成的任务匹配上。
大量的数学背景知识可能大家都忘了,但是每天敲代码的习惯并没有落下,所以说不定以优秀的深度学习开源框架代码学习入手,也是一个很好的神经网络学习切入点。
这里给大家整理和分享的是使用非常广泛的深度学习框架caffe,这是一套最早起源于Berkeley的深度学习框架,广泛应用于神经网络的任务当中,大量paper的实验都是用它完成的,而国内电商等互联网公司的大量计算机视觉应用也是基于它完成的。代码结构清晰,适合学习。
2.Caffe代码结构
2.1 总体概述
典型的神经网络是层次结构,每一层会完成不同的运算(可以简单理解为有不同的功能),运算的层叠完成前向传播运算,“比对标准答案”之后得到“差距(loss)”,还需要通过反向传播来求得修正“积木块结构(参数)”所需的组件,继而完成参数调整。
所以caffe也定义了环环相扣的类,来更好地完成上述的过程。我们看到这里一定涉及数据,网络层,网络结构,最优化网络几个部分,在caffe中同样是这样一个想法,caffe的源码目录结构如下。
在很多地方都可以看到介绍说caffe种贯穿始终的是Blob,Layer,Net,Solver这几个大类。这四个大类分别负责数据传输、网络层次、网络骨架与参数求解策略,呈现一个自下而上,环环相扣的状态。在源码中可以找到对应这些名称的实现,详细说来,这4个部分分别负责:
- Blob:是数据传输的媒介,神经网络涉及到的输入输出数据,网络权重参数等等,其实都是转化为Blob数据结构来存储的。
- Layer:是神经网络的基础单元,层与层间的数据节点、前后传递都在该数据结构中被实现,因神经网络网络中设计到多种层,这里layers下实现了卷积层、激励层,池化层,全连接层等等“积木元件”,丰富度很高。
- Net:是网络的整体搭建骨架,整合Layer中的层级机构组成网络。
- Solver:是网络的求解优化策略,让你用各种“积木”搭建的网络能最适应当前的场景下的样本,如果做深度学习优化研究的话,可能会修改这个模块。
2.2 代码阅读顺序建议
在对整体的结构有一个大致的印象以后,就可以开始阅读源码了,一个参考的阅读顺序大概是:
Step 1. caffe.proto:对应目录 caffe-master\src\caffe\proto\caffe.proto
Step 2. Hpp文件:包括
- a solver.hpp — caffe-master\include\caffe\net.hpp
- b net.hpp — caffe-master\include\caffe\net.hpp
- c layer.hpp — caffe-master\include\caffe\layer.hpp
- d blob.hpp — caffe-master\include\caffe\blob.hpp
上面d,c,b,a这4个部分实际上是自底向上的结构。
Step 3. Cpp/cu文件:对应上面提到的blob、net、solver的具体实现,所以你会看到blob.cpp,net.cpp,solver.cpp,但是注意,没有layer.cpp,而是可以看到\src\caffe\layers下有派生出的各种对应各种神经网络层的类,比如\src\caffe\layers\data_layer.cpp, conv_layer.cpp, relu_layer.cpp, pooling_layer.cpp, inner_product_layer.cpp等。(通常说来,caffe框架已经实现了很通用的网络结构,如果有自己的需求,添加一些新的层次即可)
Step 4. tools文件caffe提供的工具,目录在caffe-master\tools,例如计算图像均值,调优网络,可视化等。
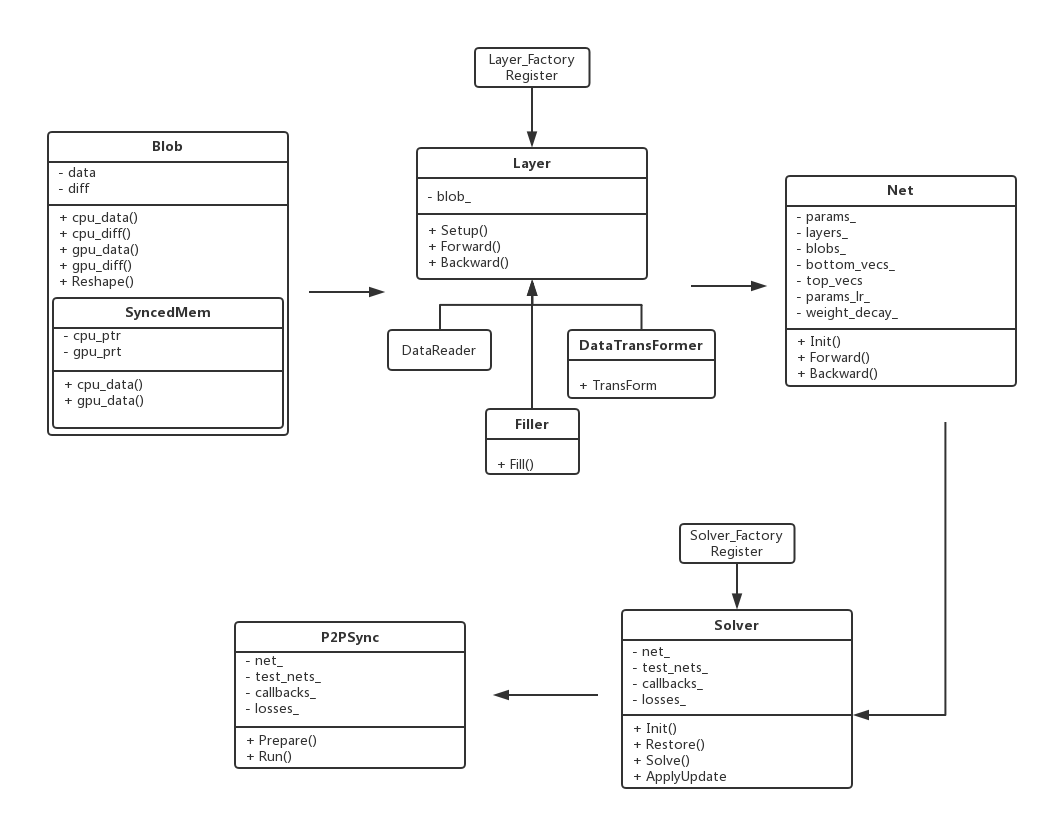
2.3 源码主线结构图
caffe代码的一个精简源码主线结构图如下:
2.4 代码细节
2.4.1 caffe.proto
caffe.proto是建议第一个阅读的部分,它位于…\src\caffe\proto目录下。首先要说明的是Google Protocol Buffer(简称 Protobuf) 是Google 公司内部的混合语言数据标准,是一种轻便高效的结构化数据存储格式,可以用于结构化数据串行化,或者说序列化。用来做数据存储或 RPC 数据交换格式。caffe.proto运行后会生成caffe.pb.cc和caffe.pb.h两个文件,包含了很多结构化数据。
caffe.proto的一个message定义了一个需要传输的参数结构体,Package caffe可以把caffe.proto里面的所有文件打包存在caffe类里面。大致的代码框架如下:
package caffe;
message BlobProto {...}
message BlobProtoVector {...}
message Datum {...}
...
message V0LayerParameter {...}
一个message定义了一个需要传输的参数结构体,Required是必须有值的, optional是可选项,repeated表示后面单元为相同类型的一组向量。比如:
message NetParameter {
optional string name = 1; // consider giving the network a name
// DEPRECATED. See InputParameter. The input blobs to the network.
repeated string input = 3;
// DEPRECATED. See InputParameter. The shape of the input blobs.
repeated BlobShape input_shape = 8;
// 4D input dimensions -- deprecated. Use "input_shape" instead.
// If specified, for each input blob there should be four
// values specifying the num, channels, height and width of the input blob.
// Thus, there should be a total of (4 * #input) numbers.
repeated int32 input_dim = 4;
// Whether the network will force every layer to carry out backward operation.
// If set False, then whether to carry out backward is determined
// automatically according to the net structure and learning rates.
optional bool force_backward = 5 [default = false];
// The current "state" of the network, including the phase, level, and stage.
// Some layers may be included/excluded depending on this state and the states
// specified in the layers' include and exclude fields.
optional NetState state = 6;
// Print debugging information about results while running Net::Forward,
// Net::Backward, and Net::Update.
optional bool debug_info = 7 [default = false];
// The layers that make up the net. Each of their configurations, including
// connectivity and behavior, is specified as a LayerParameter.
repeated LayerParameter layer = 100; // ID 100 so layers are printed last.
// DEPRECATED: use 'layer' instead.
repeated V1LayerParameter layers = 2;
}
Caffe.proto每个message在编译后都会自动生成一些函数,大概是这样一个命名规范:Set_+field 设定值的函数命名,has_ 检查field是否已经被设置, clear_用于清理field,mutable_用于设置string的值,_size用于获取 重复的个数。
大概有这么些Message类别:
属于blob的:BlobProto, BlobProtoVector, Datum。
属于layer的:FillerParameter, LayerParameter, ArgMaxParameter, TransformationParameter, LossParameter, AccuracyParameter, ConcatParameter, ContrastiveLossParameter, ConvolutionParameter, DataParameter, DropoutParameter, DummyDataParameter, EltwiseParameter, ExpParameter, HDF5DataParameter, HDF5OutputParameter, HingeLossParameter, ImageDataParameter, InfogainLossParameter, InnerProductParameter,
LRNParameter, MemoryDataParameter, MVNParameter, PoolingParameter, PowerParameter, PythonParameter, ReLUParameter, SigmoidParameter, SliceParameter, SoftmaxParameter, TanHParameter, ThresholdParameter等。
属于net的:NetParameter, SolverParameter, SolverState, NetState, NetStateRule, ParamSpec。
2.4.2 Blob
前面说到了Blob是最基础的数据结构,用来保存网络传输 过程中产生的数据和学习到的一些参数。比如它的上一层Layer中会用下面的形式表示学习到的参数:vector<shared_ptr<Blob<Dtype> > > blobs_;里面的blob就是这里定义的类。
部分代码如下:
template <typename Dtype>
class Blob {
public:
Blob()
: data_(), diff_(), count_(0), capacity_(0) {}
/// @brief Deprecated; use <code>Blob(const vector<int>& shape)</code>.
explicit Blob(const int num, const int channels, const int height, const int width);
explicit Blob(const vector<int>& shape);
/// @brief Deprecated; use <code>Reshape(const vector<int>& shape)</code>.
void Reshape(const int num, const int channels, const int height,
const int width);
...
其中template <typename Dtype>表示函数模板,Dtype可以表示int,double等数据类型。Blob是四维连续数组(4-D contiguous array, type = float32), 如果使用(n, k, h, w)表示的话,那么每一维的意思分别是:
- n: number. 输入数据量,比如进行sgd时候的mini-batch大小。
- c: channel. 如果是图像数据的话可以认为是通道数量。
- h,w: height, width. 如果是图像数据的话可以认为是图片的高度和宽度。
实际Blob在(n, k, h, w)位置的值物理位置为((n * K + k) * H + h) * W + w。
Blob内部有两个字段data和diff。Data表示流动数据(输出数据),而diff则存储BP的梯度。
关于blob引入的头文件可以参考下面说明做理解:
#include “caffe/common.hpp”单例化caffe类,并且封装了boost和cuda随
机数生成的函数,提供了统一接口。
#include “caffe/proto/caffe.pb.h”上一节提到的头文件
#include “caffe/syncedmem.hpp”主要是分配内存和释放内存的。而class SyncedMemory定义了内存分配管理和CPU与GPU之间同步的函数。Blob会使用SyncedMem自动决定什么时候去copy data以提高运行效率,通常情况是仅当gnu或cpu修改后有copy操作。
#include “caffe/util/math_functions.hpp”封装了很多cblas矩阵运算,基本是矩阵和向量的处理函数。
关于Blob里定义的函数的简单说明如下:
Reshape()可以改变一个blob的大小;ReshapeLike()为data和diff重新分配一块空间,大小和另一个blob的一样;Num_axes()返回的是blob的大小;Count()计算得到count=numchannelsheight*width。Offset()可得到输入blob数据(n,c,h,w)的偏移量位置;CopyFrom()从source拷贝数据,copy_diff来作为标志区分是拷贝data还是 diff。FromProto()从proto读数据进来,其实就是反序列化。ToProto()把blob数据保存到proto中。 ShareDate()/ShareDiff()从other的blob复制data和diff的值;
2.4.3 Layer
Layer是网络的基本单元(“积木”),由此派生出了各种层类。如果做数据特征表达相关的研究,需要修改这部分。Layer类派生出来的层类通过这 实现两个虚函数Forward()和Backward(),产生了各种功能的 层类。Forward是从根据bottom计算top的过程,Backward则刚好相反。
在网路结构定义文件(*.proto)中每一层的参数bottom和top数目 就决定了vector中元素数目。
一起来看看Layer.hpp
#include <algorithm>
#include <string>
#include <vector>
#include "caffe/blob.hpp"
#include "caffe/common.hpp"
#include "caffe/layer_factory.hpp"
#include "caffe/proto/caffe.pb.h"
#include "caffe/util/math_functions.hpp"
/**
Forward declare boost::thread instead of including boost/thread.hpp
to avoid a boost/NVCC issues (#1009, #1010) on OSX.
*/
namespace boost { class mutex; }
namespace caffe {
...
template <typename Dtype>
class Layer {
public:
/**
* You should not implement your own constructor. Any set up code should go
* to SetUp(), where the dimensions of the bottom blobs are provided to the
* layer.
*/
explicit Layer(const LayerParameter& param)
: layer_param_(param), is_shared_(false) {
// Set phase and copy blobs (if there are any).
phase_ = param.phase();
if (layer_param_.blobs_size() > 0) {
blobs_.resize(layer_param_.blobs_size());
for (int i = 0; i < layer_param_.blobs_size(); ++i) {
blobs_[i].reset(new Blob<Dtype>());
blobs_[i]->FromProto(layer_param_.blobs(i));
}
}
}
virtual ~Layer() {}
...
Layer中三个重要参数:
LayerParameter layer_param_;这个是protobuf文件中存储的layer参数。
vector<share_ptr<Blob<Dtype>>> blobs_;这个存储的是layer学习到的参数。
vector<bool> param_propagate_down_;这个bool表示是否计算各个 blob参数的diff,即传播误差。
包含了一些基本函数:
Layer()尝试从protobuf读取参数; SetUp()根据实际的参数设置进行实现,对各种类型的参数初始化;
Forward()和Backward()对应前向计算和反向更新,输入统一都是 bottom,输出为top,其中Backward里面有个propagate_down参数, 用来表示该Layer是否反向传播参数。
Caffe::mode()具体选择使用CPU或GPU操作。
2.4.4 Net
Net是网络的搭建部分,将Layer所派生出层类组合成网络。 Net用容器的形式将多个Layer有序地放在一起,它自己的基本功能主要 是对逐层Layer进行初始化,以及提供Update( )的接口用于更新网络参数, 本身不能对参数进行有效地学习过程。
vector<shared_ptr<Layer<Dtype> > > layers_;
Net也有它自己的Forward()和Backward(),他们是对整个网络的前向和反向传导,调用可以计算出网络的loss。
Net由一系列的Layer组成(无回路有向图DAG),Layer之间的连接由一个文本文件描述。模型初始化Net::Init()会产生blob和layer并调用Layer::SetUp。 在此过程中Net会报告初始化进程。这里的初始化与设备无关,在初始化之后通过Caffe::set_mode()设置Caffe::mode()来选择运行平台CPU或 GPU,结果是相同的。
里面比较重要的函数的简单说明如下:
Init()初始化函数,用于创建blobs和layers,用于调用layers的setup函数来初始化layers。
ForwardPrefilled()用于前馈预先填满,即预先进行一次前馈。
Forward()把网络输入层的blob读到net_input_blobs_,然后进行前馈,计 算出loss。Forward的重载,只是输入层的blob以string的格式传入。
Backward()对整个网络进行反向传播。
Reshape()用于改变每层的尺寸。 Update()更新params_中blob的值。
ShareTrainedLayersWith(Net* other)从Other网络复制某些层。
CopyTrainedLayersFrom()调用FromProto函数把源层的blob赋给目标 层的blob。
ToProto()把网络的参数存入prototxt中。
bottom_vecs_存每一层的输入blob指针
bottom_id_vecs_存每一层输入(bottom)的id
top_vecs_存每一层输出(top)的blob
params_lr()和params_weight_decay()学习速率和权重衰减;
blob_by_name()判断是否存在名字为blob_name的blob;
FilterNet()给定当前phase/level/stage,移除指定层。
StateMeetsRule()中net的state是否满足NetStaterule。
AppendTop()在网络中附加新的输入或top的blob。
AppendBottom()在网络中附加新的输入或bottom的blob。
AppendParam()在网络中附加新的参数blob。
GetLearningRateAndWeightDecay()收集学习速率和权重衰减,即更新params_、params_lr_和params_weight_decay_ ;
更多细节可以参考这篇博客
2.4.5 Solver
Solver是Net的求解部分,研究深度学习求解与最优化的同学会修改这部分内容。Solver类中包含一个Net指针,主要实现了训练模型参数所采用的优化算法,它所派生的类完成对整个网络进行训练。
shared_ptr<Net<Dtype> > net_;
不同的模型训练方法通过重载函数ComputeUpdateValue( )实现计算update参数的核心功能。
最后当进行整个网络训练过程(即运行Caffe训练模型)的时 候,会运行caffe.cpp中的train( )函数,而这个train函数实际上是实 例化一个Solver对象,初始化后调用了Solver中的Solve( )方法。
头文件主要包括solver.hpp、sgd_solvers.hpp、solver_factory.hpp
class Solver {...}
class SGDSolver : public Solver<Dtype>{...}
class NesterovSolver : public SGDSolver<Dtype>{...}
class AdaGradSolver : public SGDSolver<Dtype> {...}
class RMSPropSolver : public SGDSolver<Dtype> {...}
class AdaDeltaSolver : public SGDSolver<Dtype> {...}
Solver<Dtype>* GetSolver(const SolverParameter& param) {...}
包含的主要函数和介绍如下:
Solver()构造函数,初始化net和test_net两个net类,并调用init函数初始化网络,解释详见官方文档页;
Solve()训练网络有如下步骤:
- 设置Caffe的mode(GPU还是CPU)
- 如果是GPU且有GPU芯片的ID,则设置GPU
- 设置当前阶段(TRAIN还是TEST)
- 调用PreSolve函数:PreSolve()
- 调用Restore函数:Restore(resume_file)
- 调用一遍Test(),判断内存是否够
- 对于每一次训练时的迭代(遍历整个网络)
对于第7步,训练时的迭代,有如下的过程:
while (iter_++ < param_.max_iter())
1.计算loss:loss = net_->ForwardBackward(bottom_vec)
2.调用ComputeUpdateValue函数;
3.输出loss;
4.达到test_interval时调用Test()
5.达到snapshot时调用snapshot()
关于Test() 测试网络。有如下过程:
1. 设置当前阶段(TRAIN还是TEST)
2. 将test_net_指向net_,即对同一个网络操作
3. 对于每一次测试时的迭代:for (int i = 0; i < param_.test_iter(); ++i)
3.1.用下面语句给result赋值net_output_blobs_
result = test_net_->Forward(bottom_vec, &iter_loss);
3.2.第一次测试时: 取每一个输出层的blob result_vec = result[j]->cpu_data(),把每一个blob的数据(降为一维)存入一个vector–“test_score”
不是第一次测试: 用 test_score[idx++] += result_vec[k] 而不是 test_score.push_back(result_vec[k])
把输出层对应位置的blob值累加 test_score[idx++] += result_vec[k]。
3.3.是否要输出Test loss,是否要输出test_score;
3.4.设置当前阶段(TRAIN还是TEST)
基本函数的一个简易介绍如下:
Snapshot()输出当前网络状态到一个文件中;
Restore()从一个文件中读入网络状态,并可以从那个状态恢复;
GetLearningRate()得到学习率; PreSolve()提前训练,详见网页链接;
ComputeUpdateValue()用随机梯度下降法计算更新值;
未完待续…