一、项目结构
在Hadoop代码结构中,按照功能的不同将项目划分到不同目录当中。
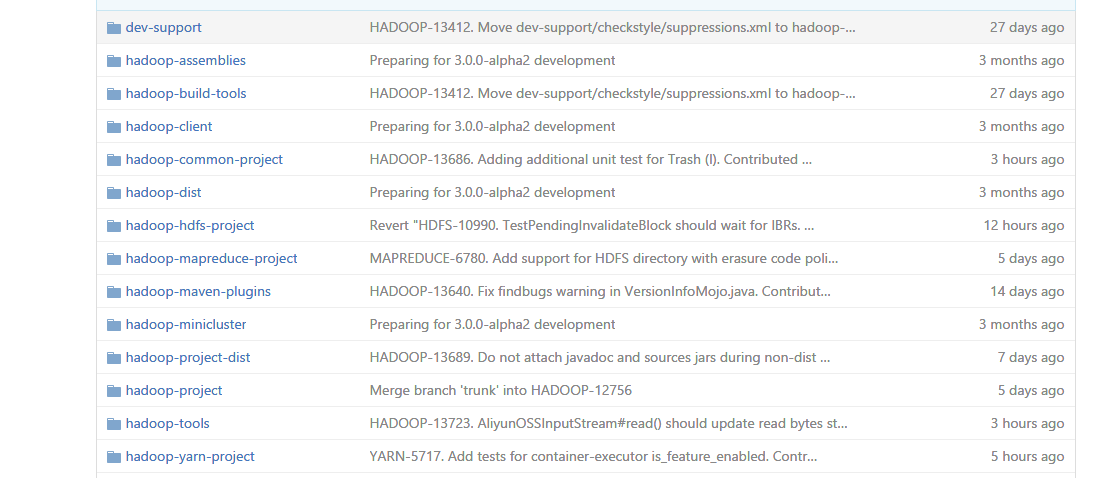
整个项目可以用maven进行构建,因此根目录下有pom.xml文件。
每个子目录也可作为独立的maven项目进行编译,因此每个子目录下也都有pom.xml。
Mapreduce、HDFS是Hadoop最主要的两个功能模块,这两个部分就分别放到了hadoop-mapreduce-project、hadoop-hdfs-project这两个目录当中。由于各子项目之间会使用些共同的基础功能,这部分基础功能的代码实现,在hadoop-common-project下。
主要子目录中的功能如下:
- hadoop-common-project:Hadoop基本功能实现,包括安全认证、日志管理、配置管理、监控等。
- hadoop-hdfs-project:HDFS功能实现。
- hadoop-mapreduce-project:Mapreduce功能实现。
- hadoop-yarn-project:Hadoop 2.x之后引入,集群资源管理框架Yarn的主要功能实现代码。
- hadoop-client:Hadoop客户端(用于作业提交、文件上传下载等)功能实现。
- hadoop-tool:第三方提供的一些工具,比如访问aliyun OSS的接口、访问aws的接口等等。
二、代码获取方法
如果只为研究目的,不考虑特殊版本需求的话,直接从apache的Hadoop官网https://hadoop.apache.org/releases.html下载一份最新的源代码。
或者,可以从github上获取:
git clone https://github.com/apache/hadoop.git
三、Eclipse项目生成及代码修改
maven的Eclipse插件可以用于生成eclipse项目文件(.classpath、.project),使得对应项目可以直接在Eclipse中打开。
在项目根目录下,可以执行:
mvn eclipse:eclipse
如上所述,Hadoop有多个子项目组成,在根目录中执行该项目之后,每个子目录都会生成单独的子项目。在Eclipse中打开就会同时载入所有子项目。
由于Hadoop项目比较大,一般会根据需要到某个子项目中执行Eclipse项目生成操作,比如:
[root@DX4-1 hadoop-2.7.2-src]# cd hadoop-common-project/
[root@DX4-1 hadoop-common-project]# mvn eclipse:eclipse
执行完成之后,可以在Eclipse中导入项目:
选择子项目所在的目录,并打开:
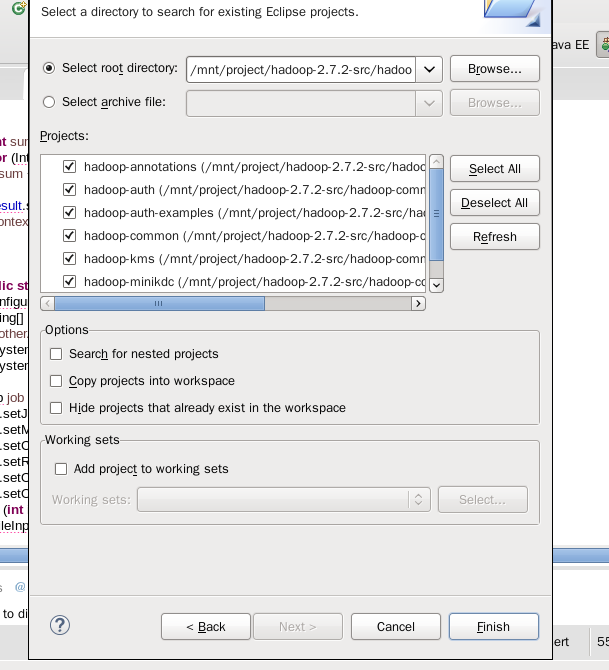
之后,便可以像平常查看普通Java项目那样,进行查找文件、跳转到定义处等操作了:
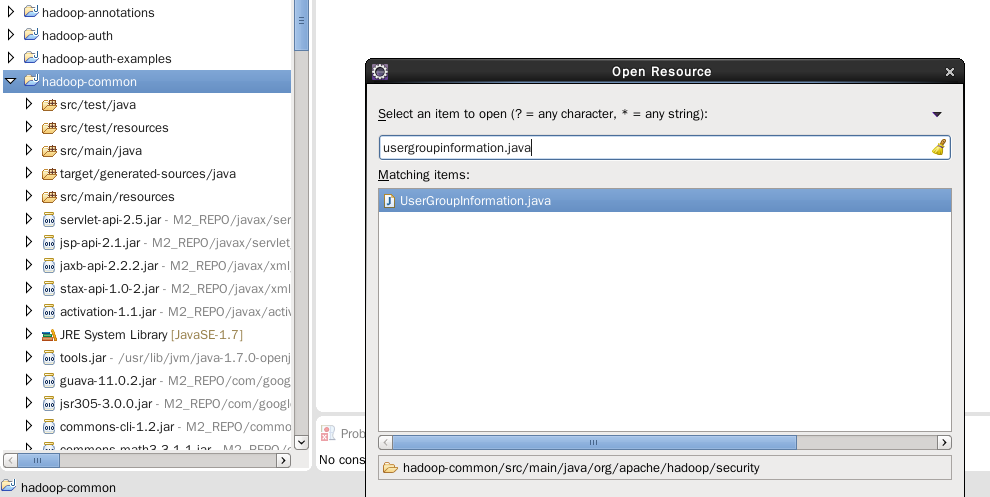
四、编译中可能遇到的问题
Hadoop的编译过程看似只需要mvn的命令启动一下即可,但过程中会对某些工具及项目有所依赖。
1、主要依赖的工具
- ant
- ant-trax
- rpmdevtools
- cmake
- lzo-devel
- openssl-devel
- snappy-devel
- forrest
如果是连上网络的一台Linux机器,装这些并不困难,在CentOS中使用yum install,在Ubuntu中使用apt-get install。
2、依赖的项目
Hadoop依赖于Google的Protobuf,需要下载、编译并安装Protobuf之后才能保证Hadoop的正确编译。
下载的链接:https://developers.google.com/protocol-buffers/docs/downloads。
需要根据需求下载正确的版本(比如Hadoop2.6.x、2.7.x需要Protobuf v2.5.0)。
解压之后,在Protobuf项目目录执行如下命令完成安装:
./configure
make
make install