一日凌晨,手机疯狂报警,短信以摧枯拉朽之势瞬间以百条的速度到达,我在睡梦中被惊醒,看到短信的部分内容如下:
Caused by: java.lang.OutOfMemoryError: unable to create new native thread
at java.lang.Thread.start0(Native Method)
at java.lang.Thread.start(Thread.java:597)
at java.util.Timer.<init>(Timer.java:154)
看到这个错误,我的第一感觉是创建了大量的线程,并且资源没有被回收,但是报错的却是其中一台应用服务器,表象看不太像是程序的问题,而此时在凌晨并发量也不应该会有这么大啊?同时我们不能因为报错暂停服务使用,而影响商户,所以决定要先解决问题,于是采用必杀技重启这台服务器,观察一小时内存溢出消失,问题暂时解决。
第二天白天这个问题并没有复现,我认为这是偶发事件,就没有过于在意,于是当晚再次出现内存溢出,并且还是随机某一台服务器爆出,我紧急找到监控部和系统部要求拿到栈信息内容和dump文件,然而并没有。。。。我们紧急开会做代码走查,发现这个应用其实是一个非常简单的应用,里面没有使用线程,也没有很复杂的逻辑,只是简单的增删改操作,那会是什么原因呢?
接下来我们的分析之路开始了。。。。。
一、现状情况
无法找到OOM时的javacore和heapdump文件。 无法还原问题发生时候系统内存被各个进程使用的占比,CPU的占比。 日志没有异常堆栈信息。
二、解决思路
1、要能够验证Tomcat配置内存溢出时打印堆栈并验证可行性,并保证在上线和重启不被擦除。 现状:当前只配置-XX:+HeapDumpOnOutOfMemoryError”,没有配置路径,不知道是被重启删除还是没有产生。
2、实现脚本,在出现OOM的时候,重启前,打印jstack栈信息和dump文件。 现状:目前是人工使用jmap和jstack打印CPU和内存信息给应急人员看。
3、实现JVM内存监控,在JVM内存紧张的时候提前报警,人工干预。 现状:无
4.、监控或者实现脚本收集java进程OOM的时候,各个进程对内存的占比等,以及监控cache, buffer等。 现状:根据凌晨OOM的情况,错误堆栈表明,start0是JVM申请系统内存时内存不够,并非jvm堆内存不够而导致,需要上面信息查看详细的系统。
5、研究底层,寻找java.lang.OutOfMemoryError: unable to create new native thread错误的引发原因有哪些。
6、针对项目进行压测发现问题点。
三、深层次测试研究
测试环境 操作系统:centos 7 64bit Linux内核:Linux centos 3.10.0-327.10.1.el7.x86_64 配置:1G内存 虚拟机工具:virtual box 64bit JDK: openjdk version “1.8.0_71” OpenJDK Runtime Environment (build 1.8.0_71-b15) OpenJDK 64-Bit Server VM (build 25.71-b15, mixed mode)
代码如下:
/**
* PROJECT_NAME: test
* CREATE BY: chao.cheng
**/
public class OOMTest {
public static void main(String[] args) throws IOException {
if (args.length < 1) {
System.out.println("please input thread numbers!");
return;
}
int threadNumber = Integer.parseInt(args[0]);
try {
for (int i = 0; i < threadNumber; i++) {
new Thread() {
public void run() {
while (true) {
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}.start();
System.out.println("Thread " + i);
}
} catch (Throwable e) {
e.printStackTrace();
}
}
}
1、第一次测试过程:
输入命令如下:
ulimit -u
显示:3584
注: ulimit -u是显示用户最多可开启的程序数目。
程序JVM参数设置如下:
java OOMTest 4000 -Xmx500m -Xss2m -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/tmp
运行结果如下:
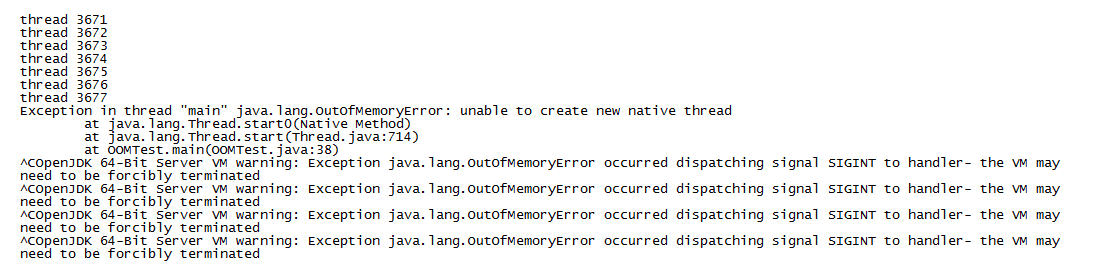
查看系统内存如下:

结论分析:
a、在tmp目录下没有生成dump文件。
我们需要注意,使用-XX:+HeapDumpOnOutOfMemoryError参数的时候,并不一定在任何溢出场景下都会产生dump文件。
b、系统内存还有很多,却无法创建线程了。感觉是系统中存在的进程/线程已经达到系统配置的极限。
2、第二次测试过程:
使用ulimit -u 65535命令或者直接修改limits.conf文件,将max user process参数修改为65535。
jvm参数配置如下:
java OOMTest 4000 -Xmx500m -Xss2m -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/tmp
程序运行结果如下: 并没有报任何错误

修改jvm参数为:
java OOMTest 40000 -Xmx500m -Xss2m -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/tmp
配置只是修改了创建线程数为40000,比上一次4000多了10倍。
程序运行结果如下:
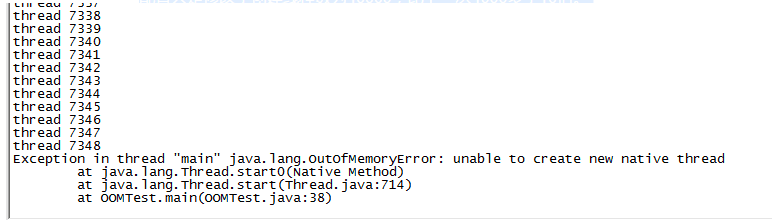
查看内存如下:
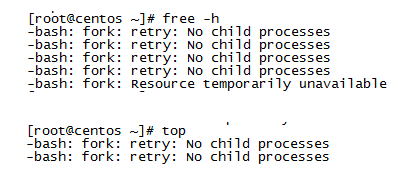
结论分析: 此时已经把系统的内存全部耗尽,无法使用free、top命令,此时已经无法执行任何命令
3、综合分析
a、当max user processers 设置的较小的时候,影响系统线程数目的是max user processers的设置
b、当max user processers设置为65535的时候,影响系统线程数目的是系统的内存。
c、对外的异常信息均为:OOM:unable to create native thread。
四、多线程内存溢出的理论支撑
通过上面的分析,我们看到其实多线程内存溢出有很大原因是因为系统设置和内存大小造成的,那么我们如何来分析当前系统配置能够支持多少线程呢?
对于java中的线程,我之前的理解一直是在java中new新线程的时候是直接使用jvm的内存,可实际情况却不是这样的。在java中每个线程需要分配线程内存,用来存储自身的线程变量,在jdk1.4中每个线程是256K的内存,在jdk1.5中每个线程是1M的内存,jdk1.6以上版本不太清楚。在java中每new一个线程,jvm都是向操作系统请求new一个本地线程,此时操作系统会使用剩余的内存空间来为线程分配内存,而不是使用jvm的内存。这样,当操作系统的可用内存越少,则jvm可用创建的新线程也就越少,我们举一个例子如下:
| 总内存 | -Xmx | -Xms | -Xss | 剩余内存 | 线程数 |
|---|---|---|---|---|---|
| 1024M | 256M | 256M | 1M | 768M | 768 |
根据上面的知识,于是衍生出了下面这样的通用公式:
(MaxProcessMemory – JVMMemory – ReservedOsMemory) / (ThreadStackSize) = Number of threads
注:
MaxProcessMemory:进程最大寻址空间。
JVMMMEMORY:jvm的内存空间(堆+永久区)-Xmx大小 (应该是实际分配大小)
ReservedOsMemory:操作系统预留内存
ThreadStackSize:-Xss大小
五、信息文件的导出
文章开始的时候说过,在内存溢出的时候,因为服务器重启导致jstack内容消失了,虽然配置了jvm参数HeapDumpOnOutOfMemoryError,但并没有产生相应的dump文件,于是我们采用脚本导出的方式,内容如下:
#!/bin/bash
ps -Leo pid,lwp,user,pcpu,pmem,cmd > /tmp/ps.log
echo 1
pid=`ps aux|grep tomcat|grep xxx|awk -F ' ' '{print $2}'`
echo 2
pstack $pid >/tmp/pstack.log
echo 3
lsof > /tmp/sys-o-files.log
echo 4
lsof -p $pid > /tmp/service-o-files.log
echo 5
jstack -l $pid > /tmp/js.log
echo 6
free -m >/tmp/free.log
echo end
vmstat 2 1
在系统异常的时候,监控系统能够自动调用脚本产生信息文件,有了这些文件分析问题才能够得心应手,不然出了问题根本无从查起,只能是没头苍蝇乱撞。
六、压测分析
在压测环境中配置与生产环境一样的硬件环境和配置环境进行压测,可以看到如下的测试图:

通过压测分析,在程序并发线程达到1010个的时候,就报出unable to create new native thread异常,查看上面这张图其实不难看出,应用程序中并没有使用线程,但是在Log4j中却大量的使用了synchronized这个关键字,在并发非常高的时候会产生非常多的阻塞,最终内存资源耗尽报出内存溢出错误。
七、问题解决方案
问题解决方案
1、优化程序,减少没用的log4j日志输出,将log4j日志改为异步+buffer的模式。 2、单台服务器本身性能有限,通过增加服务器的方式提高扩展性。 3、将系统的一些限制属性增大,如:ulimit -a。
通用解决方案
上面的四点是针对我们的解决方案,但通过以上的这些分析,我们不难发现所有的unable to create new native thread的错误异常都有其共性的地方,那接下来我再总结一些相对通用一点的方法帮助大家在以后遇到类似的问题的时候,能够有据可查知道如何进行逐步的排查。
1、当发现这个错误的时候,第一时间要排查程序是否有bug,是否大量的创建了线程,或者没有正确使用线程池,比如:是否使用了Executors.newCachedThreadPool()方法,该方法能创建Integer最大值个线程,创建到一定程度的时候系统资源耗尽就会报错。
2、如果发现程序中并没有使用线程却依然报这个错,那么观察一下这个时刻的并发情况如何,要是溢出的这一时刻比其他时候并发量都要大,这时先查看一下系统资源的情况,使用ulimit –a查看max user processes和open files这二个属性的值越大,能创建的线程数也就越大。
3、如果以上二个属性调大依然报错的话,说明此时受限于系统内存资源了,要是服务器本身内存就比较小的话,建议增加内存。要是服务器内存比较大,就需要通过调整jvm参数来增加线程使用的内存,比如减小-Xss值,这个值越小能创建的线程数也就越多,也可以适当减少-Xmx和-Xms的值,增加堆外内存的容量。
八、回顾总结
在我们排查整个内存溢出问题的过程中,其实耗费了挺长时间,而且报错的时间基本都是在晚上,分析交易量看到这个时间段的并发量确实比白天要高,给我们最大的启示是发生问题的时候,不能很快的定位问题原因,没有最重要的报错日志可供分析。基于此我们开发了JAVA探针功能,可以实时采集当前服务器的内存使用情况、JVM堆使用情况,栈使用情况等等,并且能够提前预警,界面类似下面这样:
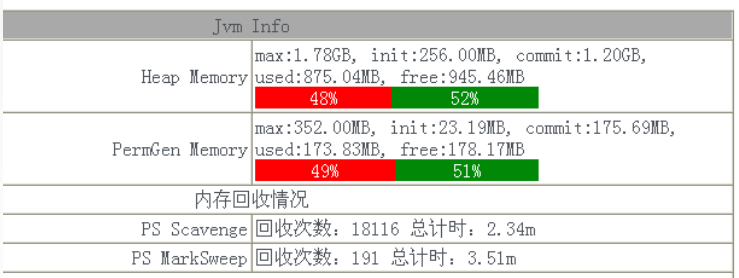
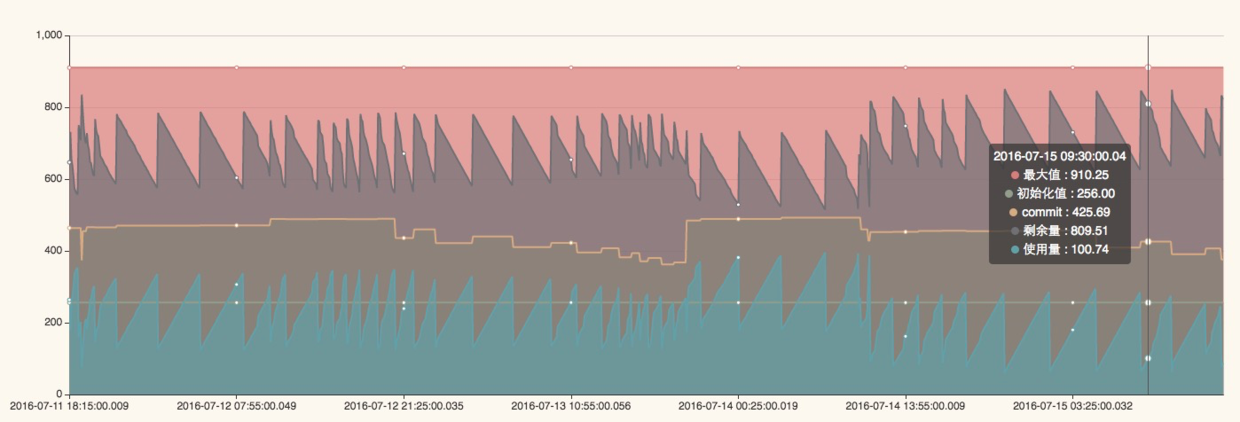
注:第一张图显示的内存使用的百分比,第二张图可以查看一段时间jvm内存使用情况,当高峰期来临时可以提前预警。